Презентация задач
Задача №1 ↓
Распознавание градовых и ливневых облаковПостановка задачи. В этой задаче необходимо было на основе методов Data Mining проанализировать значения семи признаков Х1 - Х7, характеризующих градовые и ливневые облака, представленных в виде обучающей выборки размером более 500 наблюдений (260 градовых и 256 ливневых облаков) и получить распознающую функцию для автоматизированной системы поддержки принятия решения на активное воздействие на облака. Перечень признаков приведен ниже.
Х1 – высота верхней границы радиоэхо, км;Х2 – температура на верхней границе радиоэхо, ˚C;
Х3 – отношение толщин слоев облака, расположенных при отрицательной и положительной температурах;
Х4 – максимальная по облаку радиолокационная отражаемость, см-1;
Х5 – высота максимума радиолокационной отражаемости, км;
Х6 – температура на высоте максимума радиолокационной отражаемости, ˚C;
Х7 – превышение высоты максимума отражаемости над высотой нулевой изотермы, км.
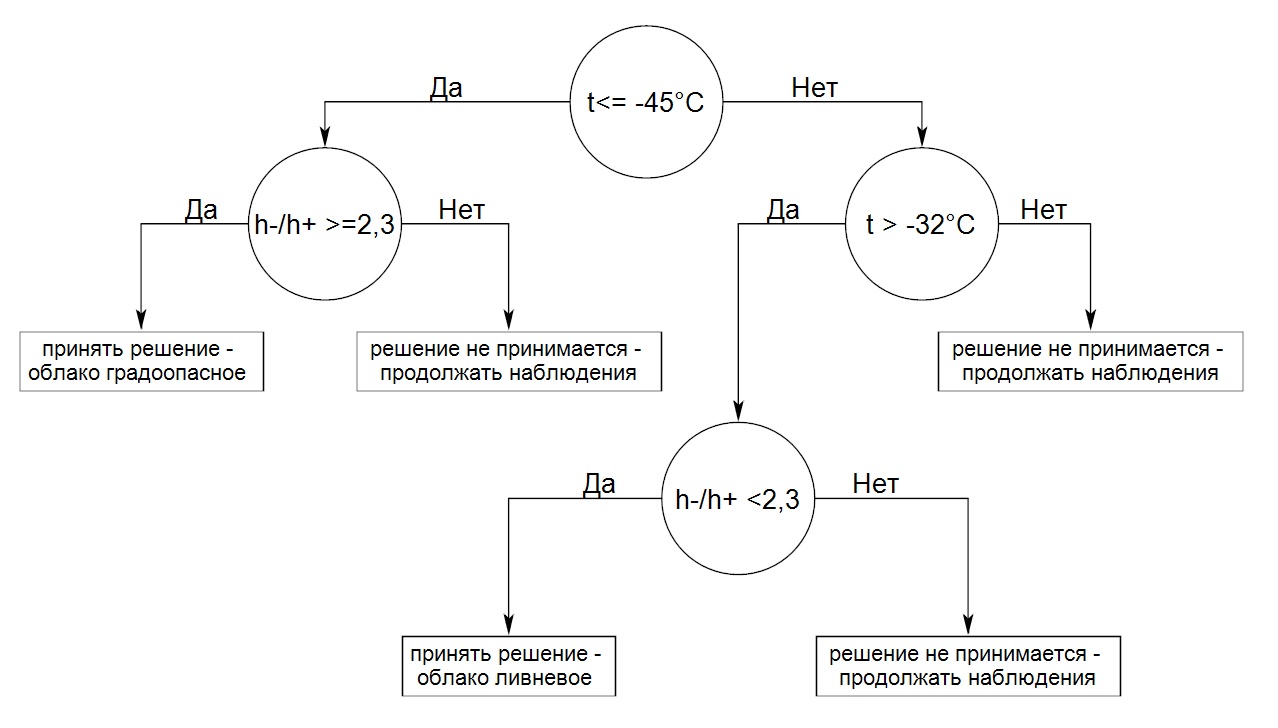
Используя разработанные нами методы поиска логико-эмпирических закономерностей в массивах экспериментальных данных, была найдена наилучшая по надежности логико-эмпирическая закономерность (распознающая функция), в которой используются два признака – Х2 (температура на верхней границе радиоэха t˚C) и Х3 (отношение толщин слоев облака, расположенных при отрицательной и положительной температурах h-/h+) и имеющая вид:
ЕСЛИ температура на верхней границе радиоэха облака довольно низкая (t<= -45°C) и значительная часть облака расположена в области отрицательных температур ( h-/h+ >=2,3)ТО облако градоопасное (с вероятностью 0,93)
ИНАЧЕ решение не принимается - продолжать наблюдения.
ЕСЛИ температура на верхней границе радиоэха облака сравнительно высокая (t > -32°C) и в области отрицательных температур не расположена значительная часть облака ( h-/h+ <2,3)
ТО облако ливневое (с вероятностью 0,94).
ИНАЧЕ решение не принимается - продолжать наблюдения.
Эта логико-эмпирическая закономерность, представленная в виде распознающего дерева на рис.1 согласуется с теорией образования града, поскольку прямо или опосредованно учитывает основные условия зарождения града: повышенную водность облака, расположение значительной части облака в области отрицательных температур, а также то, что температура на верхней границе радиоэха облака достигает уровня естественной кристаллизации. Точность распознавания этой функции на независимой контрольной выборке составила 89%.
Задача №2 ↓
Распознавание экономической состоятельности отдельных районов городаПостановка задачи. В этой задаче на основе методов Data Mining необходимо было проанализировать значения тринадцати признаков Х1 - Х13, характеризующих факторы градостроительного характера, представленных в виде обучающей выборки и спрогнозировать является ли описываемый район, предъявленный к распознаванию экономически состоятельным или нет. Перечень признаков приведен ниже.
X1 – количество инвестируемых бюджетных средств в локальную территориюX2 - количество инвестируемых внебюджетных средств в локальную территорию,
X3 – потребление воды,
X4 – потребление электроэнергии,
X5 – количество отходов,
X6 – цена 1 кв. м недвижимости в домах среднего класса застройки (серийных дома и типовых домах),
X7 – динамика миграционных процессов,
X8 – регулярность выплаты з/п,
X9 – регулярность выплаты пенсий,
X10 – общая криминогенная обстановка в %,
X11 – количество заасфальтированных дорог в %,
X12 – количество зарегистрированных фирм на 1000 чел.,
X13 – количество маршрутов транспорта в расчете на 1 кв.км (ежедневных авиа-, авто-, ж/д- рейсов в расчете на 1000 чел.).
Значения признаков Хi ϵ {0, 1}, где 0 – означает «ниже среднего значения по городу, 1 – выше среднего значения или равно среднему значению i –го признака по городу», i=0,…,13.
Y = 1 – означает экономически состоятельный район,Y = 2 – экономически несостоятельный район,
Y = 3 – решение не принимается, нужны дополнительные исследования.
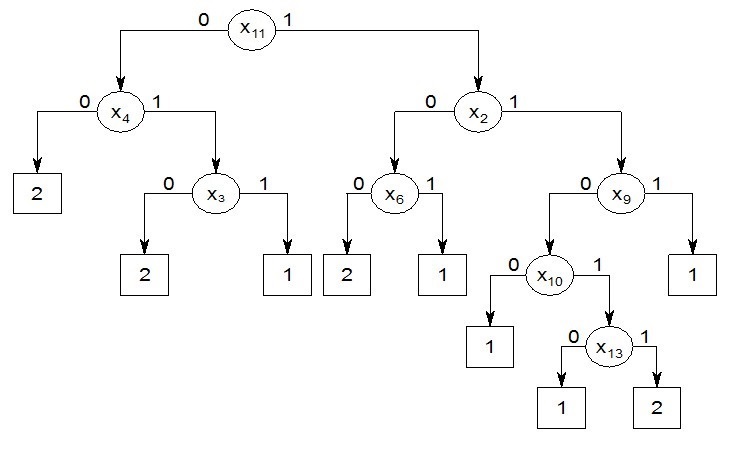
В результате обработки с помощью методов Data Mining была найдена лучшая по точности распознавания функция в виде распознающего дерева, которая представлена на рис.2. Точность распознавания составила свыше 80%.
Задача №3 ↓
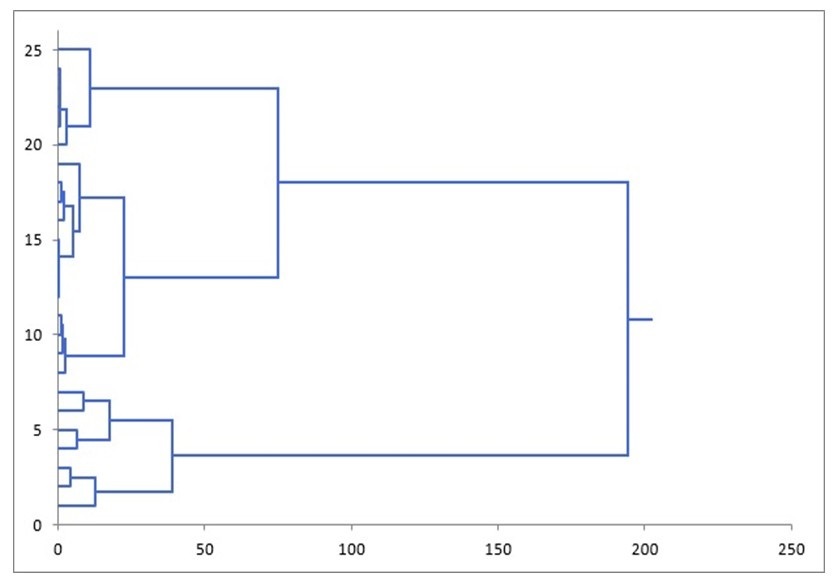
Выделение типов клиентовПостановка задачи. Имеется заполненная таблица объект-свойство (ТОС). Каждая строка-объект этой таблицы – это некоторый набор возможных значений свойств (признаков) таблицы и фактически представляет собой описание посетителя магазина. Свойства (признаки) касаются характеристик изучаемого товара. Было задействовано несколько признаков, описывающих различные характеристики товара. Для выяснения и построения наилучшей маркетинговой стратегии вначале необходимо выделить имеющиеся типы покупателей. Это было сделано на основе методов кластеризации – использовался метод построения так называемой дендрограммы.
Результаты приведены на рис.3.
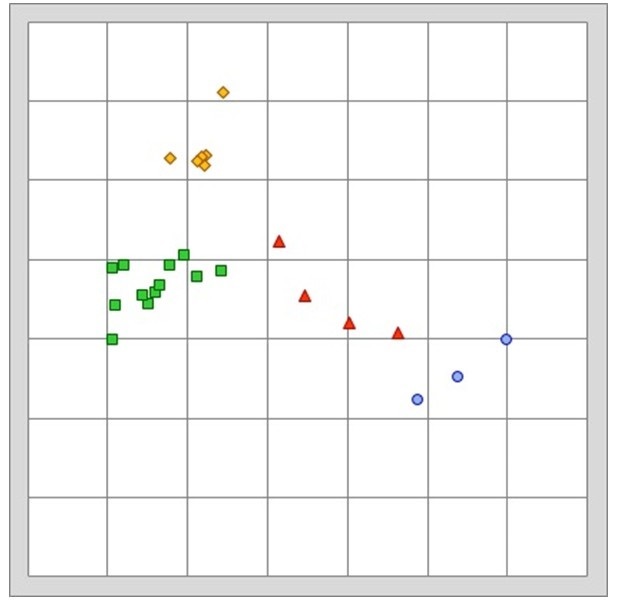
Для визуализации итоговых результатов опроса использовался также метод многомерного шкалирования. Результаты приведены на рис.4. Были определены и верифицированы отдельные группы клиентов – их можно увидеть на рисунках. Для каждой из найденных групп были определены соответствующие маркетинговые стратегии.
Задача №4 ↓
Ранняя диагностика рака молочной железы- Рак молочной железы (РМЖ) является самым распространённым злокачественным заболеванием у женщин и занимает ведущее место среди онкологических заболеваний. По данным Всемирной Организации Здравоохранения (ВОЗ) ежегодно в мире выявляется около 1 млн. новых случаев РМЖ. В Украине удельный вес женщин, больных РМЖ, в структуре заболеваемости злокачественными образованиями составляет 18,9%, а удельный вес смертности от РМЖ составляет 19,9%. Среди причин высокой смертности в Украине особенно необходимо выделить позднее выявление РМЖ и высокий показатель запущенности, который является ведущим критерием качества диагностики.
- Если диагностировать рак груди на его начальных стадиях, то 5-ти летний коэффициент выживаемости при этом заболевании составляет 98% , если раковая опухоль обнаруживается позднее, то коэффициент составляет 24%. Женщинам в возрасте от 20 до 40 лет необходимо проходить диагностику с целью обследования молочных желез не реже чем раз в 2 - 3 года, после 40 - ежегодно.
Выявления болезни на раннем этапе позволит избежать серьёзного хирургического вмешательства, которое понесёт за собой лишь удаление узлов, а не молочной железы в целом.
Ниже представлены результаты обработки по разработанным нами алгоритмам данных обследований пациентов с диагнозами – доброкачественная опухоль молочной железы и злокачественная опухоль молочной железы. Исходные данные для обработки взяты из источника: This breast cancer databases was obtained from the University of Wisconsin Hospitals, Madison from Dr. William H. Wolberg.
На рисунке внизу (рис.5) представлено одно из 54 распознающих деревьев, построенных по данным этой выборки.
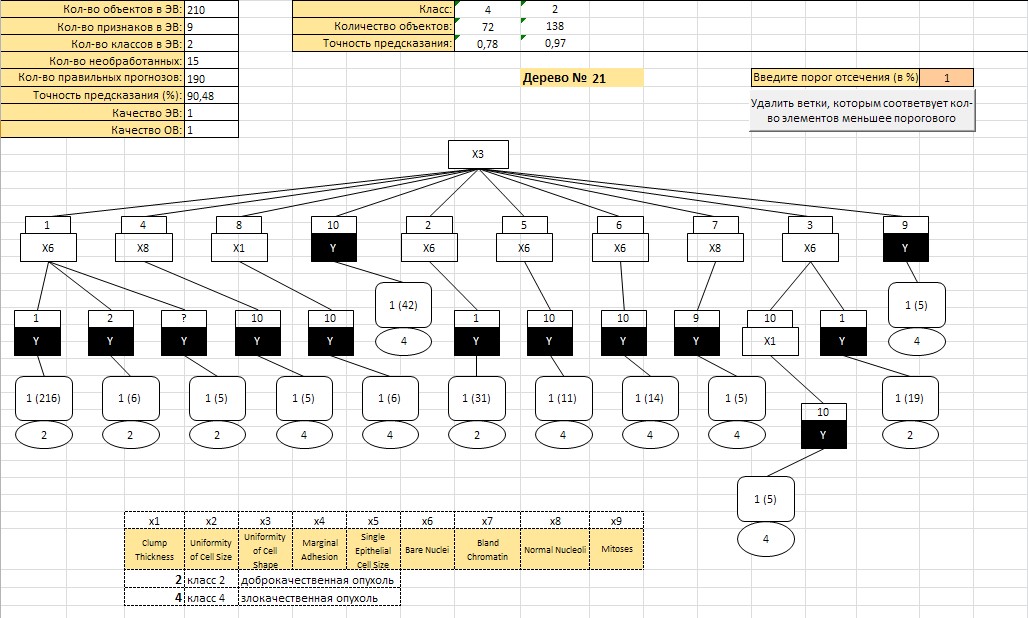
Задача №5 ↓
Автоматизация обработки медицинских изображений.Постановка задачи. Получить классификацию цифровых медицинских изображений.
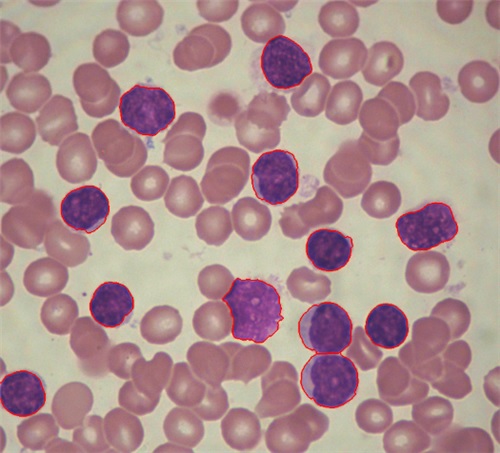
В этой задаче имеется 2 класса цифровых изображений человеческих клеток, которые представлены на рис.6. На этом рисунке выделены искомые для дальнейшей классификации клетки 1-го класса - отмечены красной границей и синим цветом, это клетки с так называемой «тенью». Остальные клетки (без «тени») относятся ко 2-му классу.
Для того, чтобы автоматически выделять (классифицировать) клетки, необходимо реализовать весь цикл типичных исследований, присущих Data Mining: определить признаки (т.е. сформировать признаковое пространство), построить обучающую выборку (ОВ) - извлечь (измерить, рассчитать) значения признаков, характеризующих клетки 1-го и 2-го классов для некоторого множества клеток, найти затем распознающую функцию для построенной ОВ, проверить ее на независимой контрольной (тестовой) выборке и затем использовать найденную распознающую функцию для решения задачи классификации клеток.
Нами был реализован такой подход, основанный на извлечении значений признаков клеток и формировании из них ОВ с последующим построением распознающей функции для классификации и который обеспечивает достаточную наглядность результатов и показывает высокую точность на тестовых данных.
Указанный цикл для большей наглядности представлен презентацией, на которую можно перейти по ссылке.
Разработанное ПО призвано повысить эффективность работы врачей при диагностике различных заболеваний, которые имеют проявления на клеточном уровне.
Задача №6 ↓
Ранняя диагностика заболеваний печени.Постановка задачи. Разработка компьютерной системы дифференциальной диагностики заболеваний печени по данным общего анализа крови и биохимического анализа крови (печеночный комплекс).
Для анализа были выбраны наиболее распространенные заболевания. Для диагностики хронических заболеваний печени важнейшими и наиболее информативными являются показатели биохимического анализа крови (печеночный комплекс), общего анализа крови и особенности клинических проявлений каждого заболевания.
Биохимический анализ крови - метод лабораторной диагностики, позволяющий оценить работу внутренних органов (печень, почки, поджелудочная железа, желчный пузырь и др.), получить информацию о метаболизме (обмен липидов, белков, углеводов), выяснить потребность в микроэлементах.
Основные показатели биохимического анализа крови (печеночный комплекс), которые оцениваются: уровень билирубина, аспартатаминотрансфераза (АСТ), аланинаминотрансфераза (АЛТ), щелочная фозфотаза, гамма-глутамилтранфераза, альбумин, калий, железо, липопротеин, гамма-глобулин, бета-глобулин.
Общий анализ крови - лабораторное исследование, которое включает в себя подсчет всех видов клеток крови (эритроцитов, лейкоцитов, тромбоцитов), определение их параметров (размеры клеток и др), лейкоцитарную формулу, измерение уровня гемоглобина, определение соотношения клеточной массы к плазме (гематокрит).
Основные показатели общего анализа крови, которые оцениваются: скорость оседания эритроцитов (СОЭ), количество эритроцитов, количество лейкоцитов, количество тромбоцитов, уровень гемоглобина.
Компьютерная система была разработана с помощью методов поиска логико-эмпирических закономерностей в массивах экспериментальных данных и анализа значений вышеперечисленных показателей, полученных у более, чем 1500 пациентов, страдающих теми или иными заболеваниями печени. Состав показателей определялся ведущими врачами на основе их опыта и квалификации. Всего в системе измеряется 10 показателей и делается вывод о наличии одного из 9 видов заболеваний. Система была проверена на независимой тестовой выборке (более 500 объектов) и показала близкое к 98% значение точности классификации заболевания. При желании Вы можете провести компьютерную диагностику, используя ссылку sciencehunter.net/Services/apps/liver.
Задача №7 ↓
Визуализация.Постановка задачи. Представить многомерную таблицу объект-свойство (ТОС) в виде множества точек на плоскости.
Одна из основных проблем кластеризации – это истинность получаемых результатов. Визуализация данных – один из способов помочь решить эту проблему. Однако визуализация кластерной структуры заданной выборки объектов, в свою очередь, также является непростой проблемой, особенно если выборка содержит большое число объектов, а пространство объектов является многомерным.
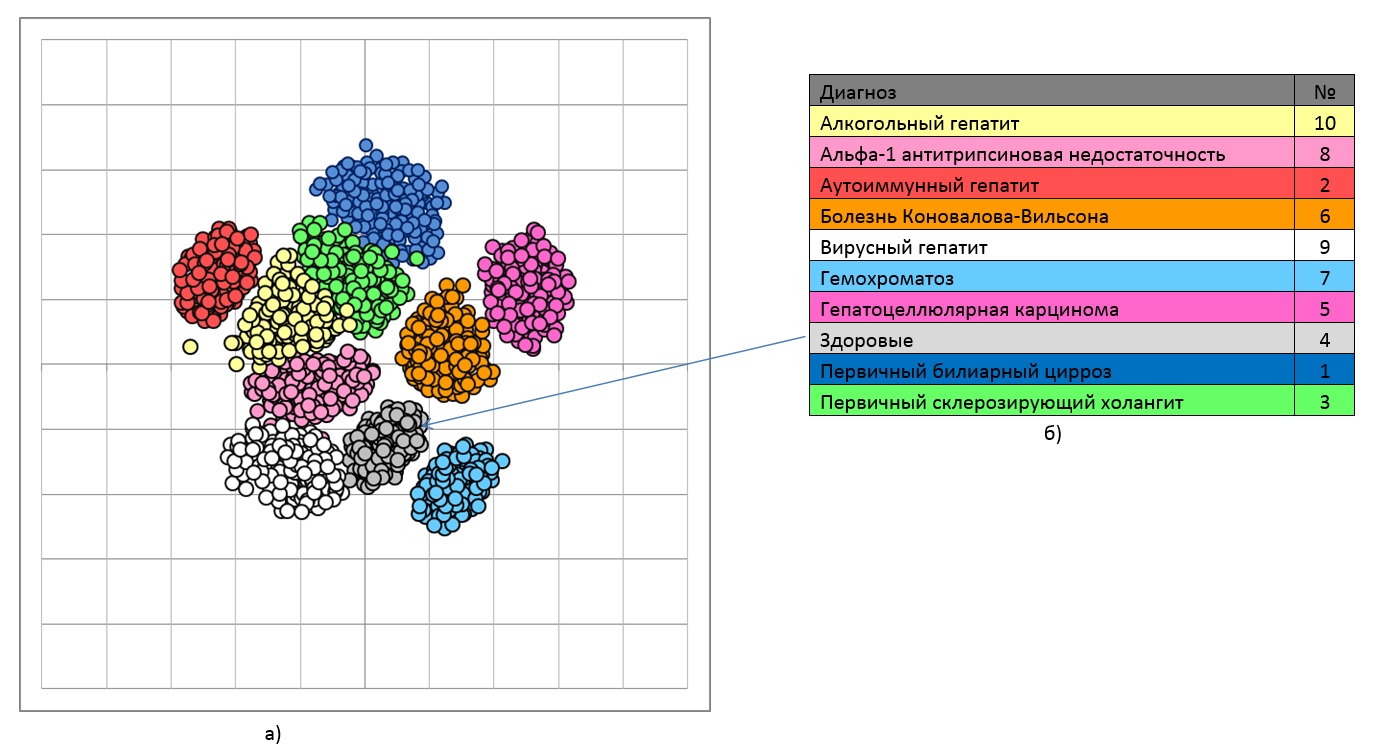
Задача многомерного шкалирования (multidimensional scaling, MDS) заключается в следующем - отобразить исходную выборку (таблицу объект-свойство - ТОС) в виде множества точек на плоскости (scatter plot). Плоское представление, как правило, искажено, но в целом отражает основные структурные особенности многомерной выборки, в частности, её кластерную структуру. Поэтому двумерное шкалирование часто используют как инструмент предварительного анализа и понимания данных, а также наглядной визуализации. Это позволяет значительно повысить удобство работы с многомерными данными. В качестве примера на рис.7 представлена кластерная структура выборки (экспериментальных данных - ТОС), по данным которой разрабатывалась компьютерная система дифференциальной диагностики заболеваний печени.
При желании Вы можете провести 3D-визуализацию, используя ссылку.
Вы можете воспользоваться сервисами размещенными на нашем портале, а также сервисом datamind.info.hazel.arvixe.com для решения некоторых важных и актуальных для практики задач в области Data Mining и анализа данных, например, таких как предварительная подготовка данных, проведение кластеризации, визуализация многомерных данных, поиск и отбор информативных признаков обучающей выборки, построение различных классификаторов, а также оценка качества обучающей выборки, что позволит вам еще до этапа построения распознающей функции выяснить верхний предел ее точности (вероятности распознавания) на объектах обучающей выборки и сэкономить таким образом ваши временные ресурсы.