Классификация
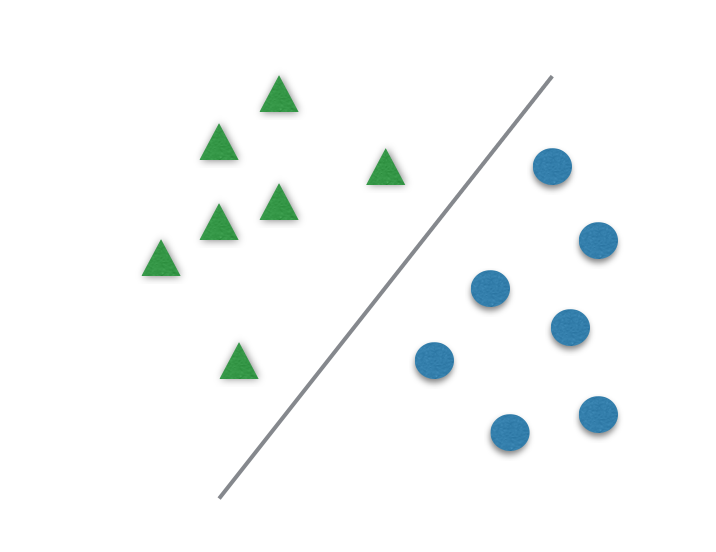
Классификация (Classification)
Классификация является наиболее простой и одновременно наиболее часто решаемой задачей Data Mining. Ввиду распространенности задач классификации необходимо четкое понимания сути этого понятия.
Под классификацией будем понимать отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Задачей классификации часто называют предсказание категориальной зависимой переменной (т.е. зависимой переменной, являющейся категорией) на основе выборки непрерывных и/или категориальных переменных.
Например, можно предсказать, кто из клиентов фирмы является потенциальным покупателем определенного товара, а кто - нет, кто воспользуется услугой фирмы, а кто - нет, и т.д. Этот тип задач относится к задачам бинарной классификации, в них зависимая переменная может принимать только два значения (например, да или нет, 0 или 1).
Другой вариант классификации возникает, если зависимая переменная может принимать значения из некоторого множества предопределенных классов. Например, когда необходимо предсказать, какую марку автомобиля захочет купить клиент. В этих случаях рассматривается множество классов для зависимой переменной.
Классификация может быть одномерной (по одному признаку) и многомерной (по двум и более признакам).
Процесс классификации
Цель процесса классификации состоит в том, чтобы построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и получает значение зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
Классификатором нназывается некая сущность (функция, модель, правило), определяющая, какому из предопределенных классов принадлежит рассматриваемый объект по вектору (набору значений) признаков.
Для проведения классификации с помощью математических методов необходимо иметь формальное описание объекта, которым можно оперировать, используя математический аппарат классификации. Таким описанием в нашем случае выступает база данных. Каждый объект (запись базы данных) несет информацию о некотором свойстве объекта.
Набор исходных данных (или выборку данных) разбивают на два множества: обучающее и тестовое.
Обучающее множество (training set) - множество, которое включает данные, использующиеся для обучения (конструирования) модели.
Такое множество содержит входные и выходные (целевые) значения примеров. Выходные значения предназначены для обучения модели.
Тестовое (test set) множество также содержит входные и выходные значения примеров. Здесь выходные значения используются для проверки работоспособности модели.
Процесс классификации состоит из двух этапов: конструирования модели и ее использования.
-
Конструирование модели: описание множества предопределенных классов.
- Каждый пример набора данных относится к одному предопределенному классу.
- На этом этапе используется обучающее множество, на нем происходит конструирование модели.
- Полученная модель представлена классификационными правилами, деревом решений или математической формулой.
-
Использование модели: классификация новых или неизвестных значений.
-
Оценка правильности (точности) модели.
- Известные значения из тестового примера сравниваются с результатами использования полученной модели.
- Уровень точности - процент правильно классифицированных примеров в тестовом множестве.
- Тестовое множество, т.е. множество, на котором тестируется построенная модель, не должно зависеть от обучающего множества.
- Если точность модели допустима, возможно использование модели для классификации новых примеров, класс которых неизвестен.
-
Оценка правильности (точности) модели.
Методы, применяемые для решения задач классификации
Для классификации используются различные методы. Основные из них:
- классификация с помощью деревьев решений;
- байесовская (наивная) классификация;
- классификация при помощи искусственных нейронных сетей;
- классификация методом опорных векторов;
- статистические методы, в частности, линейная регрессия;
- классификация при помощи метода ближайшего соседа;
- классификация CBR-методом;
- классификация при помощи генетических алгоритмов.
Вы также можете воспользоваться сервисами на сайте sciencehunter.net для классификации данных.
Для получения более подробных сведений Вы можете обратиться к нашему электронному учебнику в разделы: